Day9 TensorFlow.js: MNIST 手寫數字辨識
昨天基本上針對最簡單的回歸問題求解
熟悉一下TensorFlow的處理流程
1.準備模型(定義神經網路層->設定最佳化方法與損失計算方法)
2.拿到資料,對資料轉成tensor並正規化
3.訓練模型
4.使用模型
順便把結果視覺化出來。
今天就是開始學習辨識
機器學習領域的Hello World! ->MNIST手寫數字資料辨識
MNIST的資料官網
下載與之相對的資料處理js檔
記得刪掉import跟export 只要依順序載入檔案就行
然後跟昨天一樣來準備個模型
function createModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
//新增卷積層
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
//池化層
model.add(tf.layers.maxPooling2d({
poolSize: [2, 2],
strides: [2, 2]
}));
//重複一個卷積層一個池化層
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({
poolSize: [2, 2],
strides: [2, 2]
}));
// 扁平層轉化剛剛的二維資訊變成一維,好讓1-10被辨識出來
model.add(tf.layers.flatten());
// 最後出來得結果要是0-9共10個答案
model.add(tf.layers.dense({
units: 10,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// 定義損失函數
model.compile({
optimizer: tf.train.adam(),
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
有關這個模型為什麼是長這樣,就必須先了解CNN(Convolutional Neural Network卷積神經網路)
先看看CNN的結構圖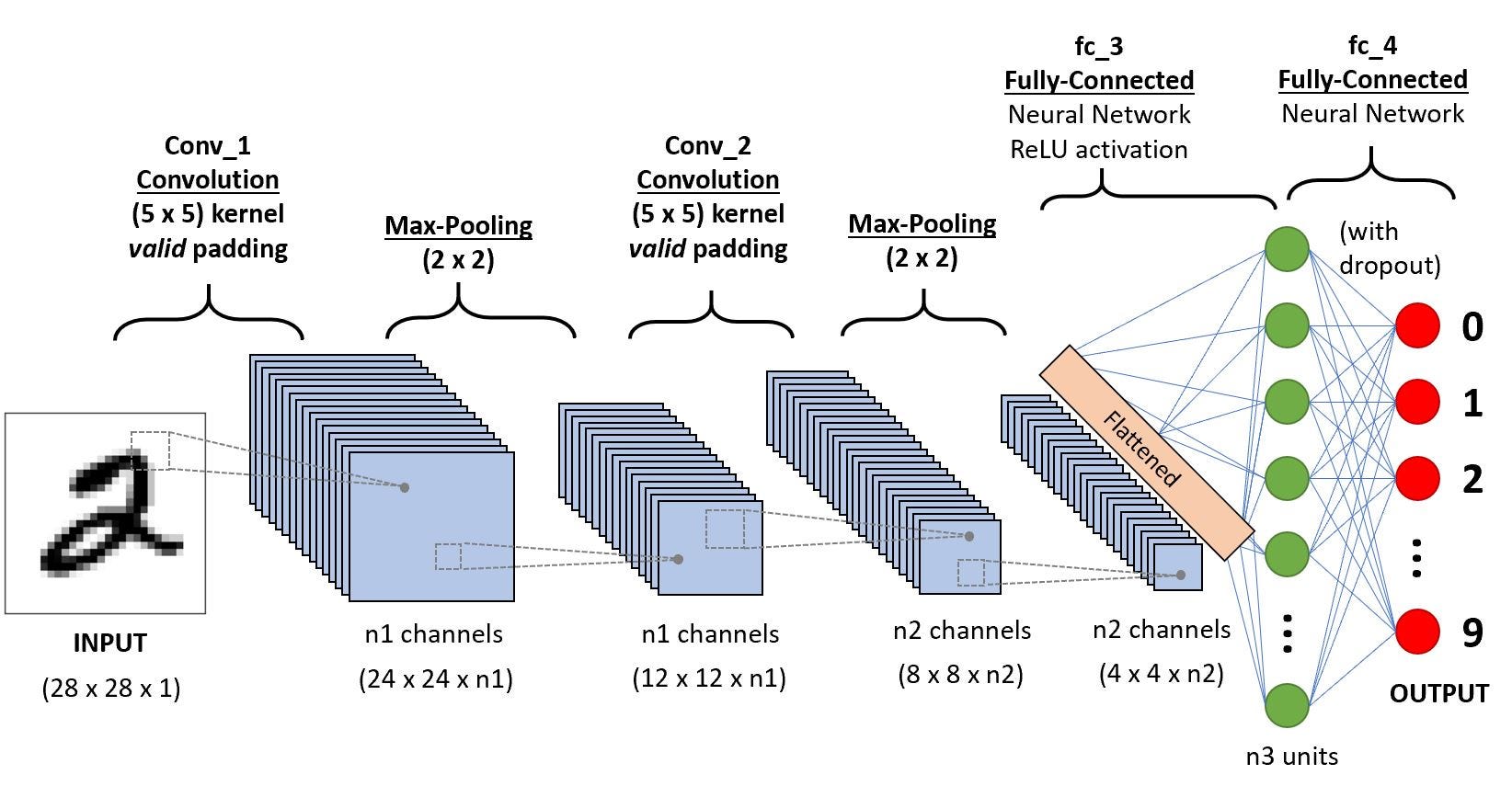
取自A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way
中間又必須了解NN的運作的理解,
不過我還沒想得很清楚怎麼表達(畫圖實在太累了)
先跳過那部分的筆記,等到之後再來補
這邊是因為不講清楚CNN,以後看這裡會看不懂
首先是卷積層
取固定大小內的像素(也就是上面定義的kernelSize)
透過一個特徵選取矩陣決定這個矩陣哪些像素要加強,那些像素要降低
像做邊緣檢測一樣.....(想到之前修平行的時候,做影像處理,真的搞很久才懂)
右下角是各自的特徵選取矩陣(kernelSize=3)
在整個卷積層中,會隨機產生多個不同的特徵選取矩陣(也就是上面定義的filters)
stride表示取完一橫排後
會像下幾格取下一個橫排
所以會看到卷積層內會產生多張被處理過後的圖
並透過ReLU去掉可能算出的像素值是負的部分
池化層,其實可以把它想像成馬賽克
取固定大小內的像素(poolSize)
通通用一個數字表達,取最大、平均.....
stride表示取完一個向右2格
取完一橫排會像下2格取下一個橫排
簡單來說,就是會簡化卷積層上的特徵圖,讓之後計算方便一點,也可以讓其對每個像素敏感度不要那麼高。
取自cs231n.github
今天花很多時間在了解CNN,沒什麼時間完成整個部分,明天再補

